 Par François Chesnais
Par François Chesnais
Dans mon article sur les rapports entre ondes longues et la technologie publié en septembre, j’ai suivi la chronologie en longue période des révolutions industrielles proposée par Robert Gordon. J’ai donc inclus comme il le fait «la robotique, la collecte et le traitement de données en masse» dans la «troisième révolution industrielle», dont les caractéristiques en termes d’investissement et d’emploi font qu’elle n’est pas porteuse d’une nouvelle onde, mais fournit au capital et aux Etats une capacité sans précédent de contrôle politique et social» [1]. D’autres auteurs, notamment Michel Aglietta, considèrent au contraire que nous vivons la «quatrième révolution industrielle» [2] dont le cœur serait ce que beaucoup nomment l’intelligence artificielle (IA), plus exactement l’ère des algorithmes.
L’objectif de l’article est de ne pas laisser la critique sociale et politique de l’intelligence artificielle (IA) aux ONG[3] et d’offrir en français une présentation marxiste d’ensemble susceptible de susciter d’autres articles (j’ai trouvé en anglais quelques travaux marxistes sur les dimensions spécifiques de l’IA[4]). Les livres qu’on trouve en librairie en France tout comme les émissions de France Culture sont extrêmement acritiques et totalement lacunaires sur beaucoup des questions traitées ici. Les livres et les études anglophones sont peu cités. A partir de mes lectures de «profane», je cherche à traiter trois dimensions de l’IA ou plus précisément de développement des algorithmes dans différents champs de l’activité sociale: premièrement comme outil technologique qui a permis la construction de l’oligopole mondial ultraconcentré des plateformes numériques dont la rentabilité élevée repose sur l’appropriation et la vente des données personnelles des individus; deuxièmement comme instrument de surveillance politique aux mains des Etats, la reconnaissance faciale en étant l’outil crucial; troisièmement comme technologie qui permet de déléguer à des algorithmes des fonctions sociales essentielles dont celle de servir d’auxiliaire du système judiciaire. L’article ne prétend pas couvrir pas l’ensemble du champ de l’IA, ainsi il ne traite pas notamment de ses effets dans le domaine de la robotique industrielle.
Intelligence artificielle et intelligence humaine
Le terme IA est trompeur. Le livre coordonné par Aglietta souligne que «les programmes doivent être considérés pour ce qu’ils sont, c’est-à-dire des systèmes d’aide à la décision, en raison de leur nature même. En effet, le fonctionnement des algorithmes dépend des fonctions mathématiques utilisées par le programmeur, de la quantité d’information entrée dans le système, du choix des paramètres fait par le programmeur».[5] On trouve chez Hubert Krivine l’analyse éclairante des progrès scientifiques et technologiques faits sur ce plan au cours des années 2010. La décennie a vu à la fois des avancées dans les réseaux de neurones spécialisés dans le traitement d’images et l’accumulation des très grandes masses de données nécessaire au déploiement de l’algorithmique.[6]
Les neurones dits «formels» sont la pierre d’angle de l’IA. Ce sont des représentations mathématiques et informatiques des neurones biologiques, c’est-à-dire des cellules nerveuses qui assurent la transmission au cerveau de signaux bioélectriques, appelés influx nerveux. Ceux-ci ont deux propriétés physiologiques: l’excitabilité, c’est-à-dire la capacité de répondre aux stimulations et de convertir celles-ci en impulsions nerveuses et la conductivité, c’est-à-dire la capacité de transmettre les impulsions. L’IA repose sur le pilotage de représentations mathématiques et informatiques de ces deux propriétés à des fins déterminées sous la forme de valeurs numériques codées dans des algorithmes regroupés en réseaux de neurones réglés pour leur faire accomplir des tâches faites par des humains. Les réseaux de neurones fonctionnent sur la base de l’induction, c’est-à-dire l’apprentissage par l’expérience. Par confrontation avec des situations ponctuelles, ils infèrent un système de décision intégré dont l’efficacité et la fiabilité reposent sur le nombre de cas d’apprentissages effectués comme sur leur complexité par rapport à celle du problème à résoudre ou de l’opération à contrôler. En raison de leur capacité de classification et de généralisation, les réseaux de neurones sont utilisés dans des fonctions de nature statistique, que celles-ci soient simples comme le tri automatique des codes postaux ou qu’elles comportent le traitement des très grandes masses de données, à savoir le big data. Les progrès de l’apprentissage statistique, l’optimisation et le calcul distribué ont abouti à l’analyse automatique des données, ce qu’on appelle l’apprentissage machine (machine learning) où une fois un logiciel créé pour une fonction donnée, un processus d’auto-apprentissage est enclenché. Une forme d’autonomie s’installe mais elle repose toujours sur l’induction. «N’importe quelle souris, écrit H. Krivine, est infiniment plus intelligente, parce qu’elle saura s’adapter à bien des situations imprévues. Ce qui est difficile, voire impossible, pour l’IA puisqu’elle procède par généralisation de situations répertoriées.»[7]
De l’apprentissage machine, on est passé à un autre stade nommé deep learning (dont la traduction littérale est «l’apprentissage profond» et une traduction plus juste «l’apprentissage approfondi»), à savoir un ensemble de méthodes d’apprentissage automatique dans le domaine visuel qui permettent de reconnaître et de déchiffrer les images.[8] Elles ont bénéficié de la construction de machines dont la puissance de traitement permet de traiter des montants massifs de données et de la constitution de bases de données suffisamment amples pour appeler la création de systèmes de très grande taille. Le deep learning est intervenu quand les systèmes informatiques sont devenus capables d’apprendre par eux-mêmes sans suivre des codes prédéterminés en raison de la conjonction de trois facteurs: «la masse toujours plus considérable de données obtenues les réseaux de recherche et les réseaux sociaux, l’augmentation vertigineuse de la puissance des ordinateurs, et la redécouverte des ‘réseaux neuronaux’, une certaine façon de construire les connexions informatiques en rendant les points de traitement des données fortement interdépendants les uns des autres, un peu comme les neurones de notre cerveau.»[9] La nouvelle génération de technologie de téléphonie cellulaire dite la 5G va accroître encore, s’agissant de la reconnaissance des images, les possibilités de multiplication des objets connectés et le contrôle commandé, dans les domaines du véhicule sans chauffeur, de l’automatisation, de la téléchirurgie [10] et celui bien sûr de la surveillance policière et para-policière.
 Par comparaison avec les ouvrages et les rapports publiés sur l’IA aux Etats-Unis, on est frappé par la placidité sinon la complaisance des publications françaises ainsi que la volonté manifeste de beaucoup d’auteurs de se limiter à des discussions techniques. Le soutien gouvernemental à l’IA sous François Hollande et de nouveau par le gouvernement Macron-Philippe y est évidemment pour beaucoup. Le consensus vient d’être rompu par les articles publiés dans le dernier numéro de la revue Cités dont l’axe principal est la dimension politique de l’IA.
Par comparaison avec les ouvrages et les rapports publiés sur l’IA aux Etats-Unis, on est frappé par la placidité sinon la complaisance des publications françaises ainsi que la volonté manifeste de beaucoup d’auteurs de se limiter à des discussions techniques. Le soutien gouvernemental à l’IA sous François Hollande et de nouveau par le gouvernement Macron-Philippe y est évidemment pour beaucoup. Le consensus vient d’être rompu par les articles publiés dans le dernier numéro de la revue Cités dont l’axe principal est la dimension politique de l’IA.
Dans les domaines où elle peut être mise en œuvre, la gestion algorithmique permet, écrit Yves Charles Zarka, de «surmonter les hésitations, les retards, les fragilités, les incertitudes, les doutes, les erreurs, en somme les limites de l’intelligence humaine. (…) La domination traditionnelle, c’est-à-dire personnelle, s’efface devant un nouveau type de domination: celle d’un maître impersonnel et anonyme dans la plupart des secteurs de la société. (…) Un maître que l’on ne peut assigner, dont on ne peut dénoncer la responsabilité, ni accuser des maux qu’il a commis. Une sorte de maître doux, insensible autant qu’invisible, dont les résultats, sous forme de conclusions, seraient incontestables et irrécusables.»[11] Cette première facette proprement politique de l’IA s’accompagne d’un second qui est celle de son pouvoir de séduction et la capacité qu’elle a eue de se glisser dans la vie quotidienne des gens.
Un secteur économique d’un degré de concentration sans précédent
Du point de vue du mouvement de l’accumulation du capital, le terrain central sur lequel se déploie l’IA est celui de la conception d’algorithmes toujours plus sophistiqués, la construction d’ordinateurs toujours plus puissants et de la constitution par les appareils d’Etat et par un très petit nombre de groupes privés de très, très importantes bases de données (le Big Data). Dans le premier cas, l’accumulation de données est faite à partir de tous les actes administratifs concernant une population donnée, dans un but de surveillance sociale et politique. Dans le second cas qui est celui des plateformes numériques (digital platforms), elle résulte, dans différentes configurations, de la centralisation d’informations provenant automatiquement de la navigation sur Internet de particuliers et d’entreprises. Le degré de concentration et de pouvoir de monopole ressort du tableau suivant.
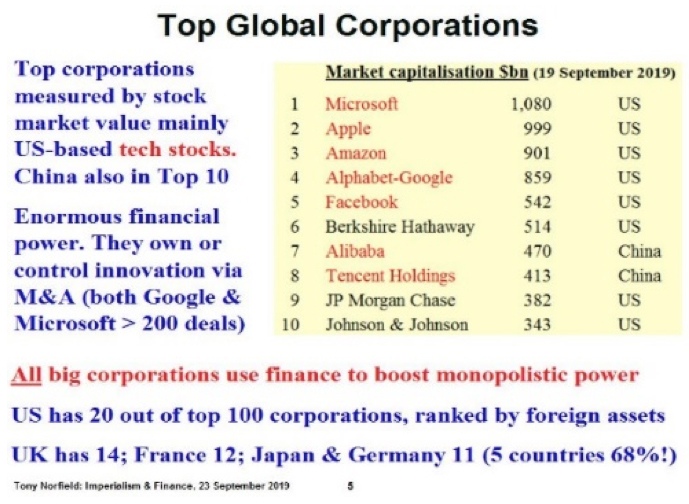
Un rapport de haute qualité entré principalement sur Google et Facebook, publié à l’intention de comités du Congrès des Etats-Unis par des chercheurs universitaires de l’université de Chicago souligne que «les marchés, où les plateformes numériques opèrent, présentent plusieurs caractéristiques économiques qui, bien qu’ils ne soient pas chacun nouveau en soi, apparaissent ensemble pour la première fois et conduisent ces marchés vers la monopolisation par une seule entreprise. Ces caractéristiques sont: i) des effets de réseau forts (plus les gens utilisent un service, plus ce service devient attrayant pour d’autres utilisateurs); ii) de fortes économies d’échelle et d’envergure (le coût de production ou d’expansion dans d’autres secteurs diminue avec la taille de l’entreprise); iii) des coûts marginaux proches de zéro (le coût de vente à un autre utilisateur est proche de zéro); (iv) des rendements élevés et croissants d’utilisation des données (plus vous contrôlez de données, meilleur est le produit/service que vous offrez); v) les faibles coûts de distribution qui permettent une portée mondiale. Cette confluence de caractéristiques signifie que ces marchés atteignent très vite un point où le marché tendra naturellement vers un seul acteur très dominant (connu en anglais sous le nom de marché où le «gagnant rafle tout» («winner takes all»). Un nouvel entrant sera très probablement incapable de surmonter les obstacles à l’entrée représentés par les économies d’échelle et le contrôle des données, car ils sont difficiles à atteindre d’une manière rapide et rentable.»[12]
Il est important de rappeler le moment et le cadre mondial de l’émergence d’un tel pouvoir de monopole. La théorie hétérodoxe en matière de technologie a établi en son temps, pour citer Giovanni Dosi, que «l’histoire d’une technologie ou encore sa trajectoire est contextuelle à l’histoire des structures industrielles qui lui sont associées. Les nouveaux paradigmes technologiques viennent de l’interaction entre les progrès scientifiques, les facteurs économiques, les variables institutionnelles et les difficultés non résolues sur les voies technologiques existantes.»[13] En suivant cette approche, on peut dire en première approximation que les formes prises par l’interaction entre les facteurs économiques et les variables institutionnelles sont indissociables du moment atteint dans le mouvement en longue période du capitalisme mondial, à savoir celui de l’achèvement du marché mondial, d’une concentration du capital toujours plus élevée et de sa financiarisation toujours plus poussée. Les voies et le terrain de déploiement de l’IA auraient-ils pu être autres? Je peux renvoyer à mon livre de 2016 et aux articles mis en ligne par A l’Encontre. Le degré atteint à la fin du 20°siècle par la concentration du capital au plan mondial sous ses trois formes ainsi que par ses traits rentiers m’inclinent à répondre que non. Si on veut un repère classique, c’est le livre de Lénine sur l’impérialisme un siècle après son achèvement. «Monopoles, oligarchie, tendances à la domination au lieu de tendances à la liberté», ou encore «bourgeoisies aux traits parasitaires nettement affirmés», autant de termes utilisés par Lénine dans le dernier chapitre de L’Impérialisme, stade suprême du capitalisme qui caractérisent aussi bien le moment historique de façon exacerbée que le fonctionnement des plateformes numériques.
Les trois groupes états-uniens qui tirent une large part de leurs profits de l’exploitation des données personnelles destinées à être vendues comme moyen de cibler des consommateurs – Google, Facebook et Amazon – ont été fondés par de très jeunes gens et ont bénéficié du financement facile du boom des dot.com. Amazon a été créé en 1994 est entré au Nasdaq en 1997. Google est né comme un projet de recherche de deux étudiants à l’université de Stanford en 1996 et sa croissance a été financée par des sociétés de venture capital avant d’entrer en bourse en 2004. Facebook est né comme un site web à l’université de Harvard en 2003 et est entré en bourse en 2012. Les fondateurs en sont toujours les actionnaires de contrôle et les dirigeants non contestés. Le tournant du XXI° siècle a vu le lancement de deux groupes chinois Alibaba et Tecent Holdings. Le contexte de l’entrée de la Chine à l’OMC lui a valu l’absence d’opposition et même une certaine coopération du capital états-unien.
Une clarification est nécessaire au sujet du terme capitalisme de surveillance. La Monthly Revue a publié en 2014 à la suite des révélations d’Edward Snowden un numéro portant ce titre. La surveillance dont il s’agissait étant celle de l’appareil d’Etat. L’emploi du terme s’est généralisé avec la publication sous ce titre en 2016 du livre de Shoshana Zuboff dont Le Monde Diplomatique a publié un article en janvier 2019.[14] Elle ne fait aucune allusion au numéro de la Monthly Review et elle introduit une certaine confusion en parlant de la «surveillance commerciale» dont Google serait le principal architecte. Ici, dans cet article le terme surveillance désigne exclusivement la surveillance étatique dont le but est la collecte et l’analyse de données à des fins «sécuritaires». Car dans le cas de Google comme de Facebook la finalité est la maximisation des profits et la collecte et l’analyse de données personnelles le moyen d’atteindre cet objectif.
L’Internet, des positions de monopole exceptionnelles et la théorie de la valeur
L’Internet est un réseau informatique mondial constitué d’un ensemble de réseaux nationaux, régionaux et privés. L’ensemble utilise un même protocole de communication: TCP/IP, (Transmission Control Protocol/Internet Protocol). Il résulte de la collaboration scientifique entre les laboratoires du département de la Défense (DARPA) et les plus grandes universités américaines. Internet est mondial. Dans chaque pays les coûts d’entretien de l’Internet sont supportés par les pouvoirs publics (gouvernements, régions et municipalités) ainsi que par les fournisseurs d’accès à Internet (FAI) pour qui c’est une activité profitable puisqu’elle leur apporte des utilisateurs en nombre croissant. Le moteur de recherche chinois Baidu est le quatrième au monde en termes d’internautes en 2015.[15] Le moteur de recherche russe se situe au cinquième rang. A l’échelle de la planète il n’y a qu’une seule «toile»: pour le moment au moins car la Russie vise à se donner les moyens de s’en déconnecter et a annoncé la réussite des tests menés.[16] Cependant la liberté de navigation sur Internet connaît des interdictions ou se heurte à des obstacles qui passent par le blocage des FAI. Ces situations sont suivies par les ONG Reporters sans frontières et OpenNet Initiative et font l’objet de rapports.[17] OpenNet distingue les pays ennemis de l’Internet et les pays où les fournisseurs d’accès sont surveillés en permanence.[18] En 2018, l’ONG a identifié 21 cas de fermetures partielles ou totales comparées à 13 en 2017 et 4 en 2016. La Chine est en tête des pays ennemis avec son objectif de construire un «grand pare-feu» (Great Firewall). La question de savoir si elle y parviendra divise les chercheurs. Les militants ont trouvé le moyen de le contourner et les réseaux sociaux se sont reconstitués avant que leur découverte n’envoie les opposants en prison.[19]
L’externalité positive[20] représentée pour eux par l’Internet permet aux grands groupes de construire des bases de données très importantes qui livrent des informations sur les internautes ensuite vendues à des entreprises qui s’en servent à cibler des clientèles. Comme le rapport des chercheurs de Chicago cité plus haut les plateformes numériques bénéficient d’un fort «effet de réseau», pouvoir d’attraction d’un réseau – ici d’une plateforme – qui a la propriété de s’accroître avec le nombre de ses utilisateurs. Pris ensemble avec les facteurs politiques dont, plus généralement, les groupes financiers à dominante industrielle et commerciale états-uniens tirent leur force (voir les menaces commerciales de Trump contre les pays voulant faire payer des impôts aux GAFA), cet ensemble de facteurs a permis à Google et à Facebook de construire des positions de monopole uniques au monde. Ils ont échappé pendant longtemps, ainsi que les autorités concernées l’ont reconnu, à toute application du droit de la concurrence. [21]
Aux Etats-Unis, les deux groupes ont été condamnés en 2019 par la Federal Trade Commission pour atteinte à la vie privée et non pour un motif relevant de la loi anti-trust. Certes en France l’Autorité de la concurrence vient de sanctionner Google pour abus de la position dominante qu’elle détient sur le marché de la publicité «en adoptant des règles de fonctionnement de sa plateforme publicitaire Google Ads opaques et difficilement compréhensibles et en les appliquant de manière inéquitable et aléatoire.»[22] Mais la pénalité financière de 150 millions d’euros est absolument dérisoire.
Venons-en à la question théorique essentielle posée par les grandes plateformes numériques, celle de leur cycle de valorisation. Les profits de leur métier de base proviennent de la vente à des fins publicitaires d’informations personnelles livrées soit par les utilisateurs au cours de leur navigation sur la «toile», du fait de leur activité comme internautes, soit de l’accès à certaines données notamment les données médicales consenties à une plateforme par des acteurs du système de soin[23]. Ces informations sont la matière première d’un cycle de valorisation rentier très particulier. En utilisant les notations classiques A-M (T+Mp) -P-M’(M’+plv) -A’[24], l’achat de la force de travail (T) et celui des moyens de production (Mp). T et Mp se confondent en partie puisque la conception d’algorithmes repose sur le savoir-faire des programmeurs, mais il y a aussi le travail des soutiers de grandes plateformes, ceux qu’Antonio Casilli nomme les «travailleurs de clic». Ils accomplissent des tâches qui prennent quelques secondes ou au plus quelques minutes pour être réalisées, qui vont de la labellisation d’images, de la retranscription de petits bouts de textes, de l’enregistrement de voix ou de l’organisation d’information. Les prolétaires du clic, salariés ou auto-entrepreneurs, font un travail de sélection et de tri de l’information, en signalant ce qui est problématique par rapport aux normes mêmes de la plateforme.[25] La troisième composante de M d’un cycle normal de valorisation, à savoir l’achat de matières premières, est obtenue gratuitement par appropriation de l’information. Le moment P est celui de sa vente sur le marché de la publicité. On peut attribuer le niveau très élevé de A’ à l’appropriation gratuite de la matière première ou y voir un cas d’appropriation de la plus-value d’un niveau sans pareil dans l’histoire du capitalisme puisque programmeurs et travailleurs du clic travaillant pour les plateformes ne dépassent pas quelques milliers de personnes.[26] Nick Srnicek se demande même au sujet de P si faire une recherche sur Google ou poster des messages sur Facebook représente du travail créateur de plus-value effectué par les internautes. Il répond par la négative et commente que cela veut dire que «ces entreprises vivent en parasite sur d’autres industries productrices de valeur et que l’état du capitalisme mondial est bien grave.»[27]
Il n’en reste pas moins que les profits très élevés à haute teneur rentière permettent aux plateformes numériques de diversifier leurs activités dans le champ de l’IA moyennant de fortes dépenses en R&D, ainsi que de procéder de façon particulièrement intense à l’acquisition de petites start-up et de fusion de groupes industriels plus petits. La capacité financière de croissance par fusions/acquisitions leur permet de s’étendre hors de leur secteur d’origine donnant aux caractéristiques monopolistiques exceptionnelles des groupes un fondement encore plus large et solide. La capacité à suivre ou non cette voie a même été déterminante dans la sélection concurrentielle féroce entre plateformes qui a vu notamment la rétrogradation puis le dépeçage de Yahoo au bénéfice notamment de Verizon alors qu’elle était un des leaders mondiaux en 2000.[28] (A suivre sur ce site, le lundi 17 février 2020)
________
[1] http://alencontre.org/laune/la-theorie-des-ondes-longues-et-la-technologie-contemporaine-i.html (dernier paragraphe).
[2] Sous la direction de Michel Aglietta, Capitalisme. Le temps des ruptures. Odile Jacob, novembre 2019.
[3] https://cdn2.nextinpact.com/medias/surveillance-giants-report.pdf
[4] La Monthly Review a publié en 2014 et en 2016 des articles sur la surveillance étatique https://monthlyreviewarchives.org/index.php/mr/issue/view/MR-066-03-2014-07 et https://monthlyreview.org/2016/05/01/mr-068-01-2016-05_0/ L’ouvrage de Nick Srnicek, Platform Capitalism, Polity, 2016 disponible en PDF à http://pombo.free.fr/srnicek17.pdf m’a servi pour l’analyse des plateformes publicitaires. L’ouvrage de Christian Fuchs and Vincent Mosco, Eds. Marx in the Age of Digital Capitalism, Brill, Leiden, 2016 a pour but de fonder une théorie marxiste de la communication à l’âge de l’Internet. J’ai pris connaissance de l’ouvrage de Nick Dyer-Witheford, Atle Mikkola Kjosen et James Steinhoff, Inhuman Power: Artificial Intelligence and the Future of Capitalism. London: Pluto Press, 2019 trop tard pour en intégrer les conclusions à cet article.
[5] Op.cit., p. 193-194.
[7] Hubert Krivine dans L’anticapitaliste, janvier 2020, https://npa2009.org/idees/culture/trois-livres-sur-lintelligence-artificielle
[8] Sur Internet on trouve de nombreux textes sur ces méthodes, dont https://siecledigital.fr/2019/01/30/differences-intelligence-artificielle-machine-learning-deep-learning/
[9] Gaspard Kœnig, La Fin de l’individu. Voyage d’un philosophe au pays de l’intelligence arti?cielle, Paris, Éditions de L’Observatoire, 2019, p. 37.
[10] https://siecledigital.fr/2019/04/23/industrie-de-demain-intelligence-artificielle-5g/
[11] Yves Charles Zarka, L’intelligence arti?cielle ou la maîtrise anonyme du monde, Revue «Cités» Presses Universitaires de France, 2019/4 N° 80, pages 5 et 6.
[12] Committee for the Study of Digital Platforms Market Structure and Antitrust Subcommittee, Stigler Center for the Study of the Economy and the State, the Booth School of Business at the University of Chicago, September 2019. https://research.chicagobooth.edu/stigler/media/news/committee-on-digitalplatforms-final-report, pages7-8.
[13] Cette définition de l’approche hétérodoxe qui a été balayée par la modélisation néo-classique est empruntée à Giovanni Dosi avant qu’il ne change de camp. Giovanni Dosi, Technological paradigms and technological trajectories: A suggested interpretation of the determinants and directions of technical change, Research Policy, vol.11/3, 1982.
[14] Shoshana Zuboff, The Age of Surveillance Capitalism: The Fight for a Human Future at the New Frontier of Power, Public Affairs, New York, NY, January 15, 2019 et Shoshana Zuboff, https://www.monde-diplomatique.fr/2019/01/ZUBOFF/59443
[15] https://www.drujokweb.fr/blog/10-choses-sur-baidu/ et https://fr.wikipedia.org/wiki/Baidu
[16] Internet russe: l’exception qui vient de loin, août 2017 https://www.monde-diplomatique.fr/2017/08/LIMONIER/57798 https://www.zdnet.fr/actualites/la-russie-totalement-deconnectee-d-internet-39896419.htm Le gouvernement russe a annoncé hier (le 23 décembre 2019) avoir conclu une série de tests au cours desquels il a réussi à déconnecter le pays de l’internet mondial. Les tests commencés la semaine dernière ont été effectués sur plusieurs jours. Ils ont impliqué des agences gouvernementales russes, des fournisseurs d’accès à Internet locaux, ainsi que des entreprises russes spécialisées dans le domaine d’Internet. L’objectif était de savoir si l’infrastructure internet nationale – connue en Russie sous le nom de RuNet – pouvait fonctionner sans accéder au système DNS général et à l’Internet extérieur. Le trafic internet a été redirigé en interne, faisant du réseau RuNet le plus gros réseau intranet du monde.
[17] https://en.wikipedia.org/wiki/Internet_censorship
[18] https://fr.wikipedia.org/wiki/Censure_de_l%27Internet#OpenNet_Initiative
[20] En économie on désigne par «externalité» ou «effet externe» le fait que l’activité de production ou de consommation d’un agent affecte le bien-être d’un autre sans qu’aucun des deux reçoive ou paye une compensation pour cet effet.
[21] Voir le rapport conjoint en anglais du Bundeskartellamt et de l’Autorité de la concurrence française https://www.autoritedelaconcurrence.fr/sites/default/files/algorithms-and-competition-summary.pdf
[22] https://www.autoritedelaconcurrence.fr/fr/article/google-sanctionne-150-millions-deuros-pour-abus-de-position-dominante. Elle inflige à Google une sanction de 150 millions d’euros et l’enjoint de clarifier la rédaction des règles de fonctionnement de Google Ads.
[23] Margo Bernelin, Intelligence arti?cielle en santé: la ruée vers les données personnelles, Revue Cités, Presses Universitaires de France, 2019/4 N° 80.
[24] A= Capital initial, M = achat de force de travail T et de moyens de production Mp, P = production, M’ = résultats de la production soit des marchandises M’ et de la plus-value, A’= Capital grossi de profit.
[25] Antonio Caselli, En attendant les robots. Enquête sur les travailleurs du clic, Seuil, Paris, 2019.
[27] Nick Srnicek, Platform Capitalism, part 2.
[28] https://en.wikipedia.org/wiki/Yahoo Aussi https://www.investopedia.com/articles/markets/121015/how-yahoo-makes-money-yhoo.asp. L’entrée en français est truffée d’erreurs et ne traduit pas la réalité.
Soyez le premier à commenter