 Par François Chesnais
Par François Chesnais
Il s’agit maintenant d’examiner les domaines où il y a délégation à des algorithmes de décisions qui étaient jusqu’à maintenant prises par des humains. Elle s’accompagne d’une déresponsabilisation de la prise de décision en faveur du «maître impersonnel et anonyme» dont les conclusions peuvent être présentées comme « incontestables et irrécusables », pour utiliser l’expression de Charles Yves Zarka dont on a parlé dans la première partie. L’examen des cas les plus saillants, notamment de façon très dangereuse dans le domaine de la justice, est suivi de la présentation de l’emploi de la reconnaissance faciale à des fins de contrôle social et policier.
La délégation de décision à des algorithmes dans la sphère de la finance
Commençons par la gestion algorithmique de portefeuilles, domaine important pour le fonctionnement du capitalisme mais où aucune question d’éthique sociale n’est posée. En octobre 2019, The Economist a publié un éditorial et un dossier sur l’utilisation des algorithmes dans la gestion des placements et des transactions sur les marchés financiers. Le titre un peu sensationnaliste «Maîtres du monde. Comment les machines s’emparent de Wall Steet?» traduit à la fois une inquiétude justifiée par la concurrence aveugle et intense qui règne dans la sphère financière et la haute idée que les éditorialistes se font de «la fonction des marchés financiers (laquelle) consiste à traiter l’information afin que l’épargne soit acheminée vers les meilleurs projets et les meilleures entreprises.» Et de louer le travail des gérants de fonds: «La haute finance peut paraître simple ; en fait, sa fonction en fait quelque chose de dynamique et d’enivrant (sic). Elle doit surveiller un monde en constante mutation. Ainsi, aujourd’hui, les marchés sont confrontés à une guerre commerciale et à des taux d’intérêt bas. Mais la finance vit aussi des changements en son sein même, une réinvention constante dans une lutte perpétuelle pour obtenir un avantage concurrentiel.» Or maintenant «les machines sont en voie de prendre le contrôle des investissements, non seulement les activités routinières d’achat et de vente de titres, mais aussi ceux qui décident de l’orientation de l’économie et de l’allocation de capitaux à partir des sommets stratégiques («commanding heights»)» [1]
Le montant du capital fictif, dont le placement est géré par des ordinateurs et des algorithmes, ce qu’on nomme le «robo-investing», représente selon The Economist 35% de la capitalisation boursière à Wall Street, 60% des actifs des investisseurs institutionnels et 60% des achats et ventes de titres sur les marchés américains. Qui dit «robot investing» dit licenciements donnant lieu au jeu de mots Goldman Sacked (du mot familier to sack = licencier).[2] Cette gestion prend différentes formes. Sur les marchés d’actions, la plus courante est celle de l’ETF (Exchange-traded fund), aussi appelé «tracker», en français, «fond commun de placement quantitatif». Il est programmé pour répliquer le plus fidèlement possible les variations d’un indice boursier à la hausse comme à la baisse. Alors que les sociétés d’investissement à capital variable (SICAV) créées par les banques étaient les véhicules de gestion traditionnels de l’épargne des particuliers, les ETF sont des fonds émis par des sociétés de gestion agréées. Puisqu’ils sont programmés pour suivre les fluctuations d’un indice de référence, sans chercher à obtenir une meilleure performance que la moyenne du marché, ils sont dits de «gestion passive». C’est en particulier dans la gestion des portefeuilles privés qu’on trouve les plates-formes d’investissement en ligne entièrement automatisées nommées «robo-conseillers».[3]
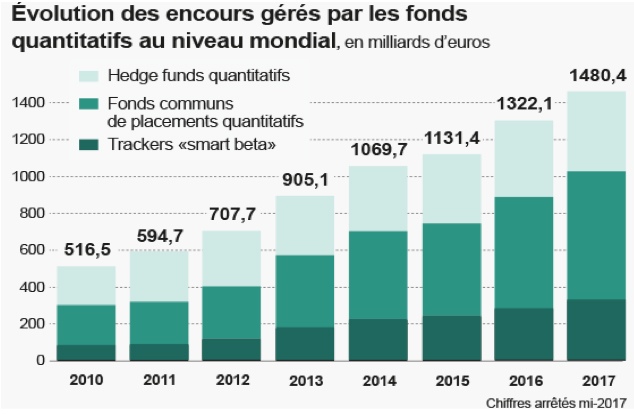
Début décembre 2019 aux Etats-Unis, une sous-commission de la Chambre des représentants s’est réunie pour discuter de l’impact futur de l’intelligence artificielle sur les marchés financiers. La discussion a porté sur une tendance dont le président de la commission s’est particulièrement inquiété, à savoir la concentration des transactions gérées par algorithmes aux mains des acteurs les plus puissants sur le marché, «les économies d’échelle dans les industries numériques permettant aux plus grandes sociétés d’investissement de traiter plus de données, trouver plus de corrélations algorithmiques et augmenter leurs profits aux dépens de leurs concurrents.»[4] De façon plus générale, on peut noter un renouveau de discussion des effets du degré atteint par la concentration avec la «montée au front» des économistes néoclassiques[5] et le début d’un nouveau cycle d’auditions au Congrès.[6]
La Fed et les institutions financières internationales voient dans la montée en puissance de la gestion automatisée la source de risques importants. Les positions brutes sur les dérivés des gestionnaires d’actifs et des fonds à effet de levier dans le cadre de contrats en eurodollars à trois mois, l’indice de référence mondial de taux d’intérêt le plus liquide, ont augmenté de 37% au cours des trois années. En comparaison, la position des banques a augmenté de 18%. Certains craignent que la croissance des transactions automatisées conduise à un fort encombrement des marchés. La BRI (Banque des règlements internationaux) a prévenu que la montée des algorithmes «rendra les marchés à la fois plus fragiles aux chocs imprévus et plus interconnectés, car des utilisateurs nombreux font appel à un nombre limité de relations de données sous-jacentes», tandis que le nombre de banques en mesure d’agir comme teneurs de marché aura fortement diminué (un teneur de marché est un opérateur qui prend l’engagement de fournir une cotation continue même en cas de chute des cours).
Enfin les GAFA ont lancé depuis quelques d’années des initiatives diverses dans le domaine de la finance. La menace est devenue plus pressante pour les grands groupes bancaires avec la conclusion de deux partenariats majeurs. D’abord celui d’Apple et sa carte de crédit en partenariat avec Goldman Sachs et maintenant le géant des plateformes publicitaires. Alphabet/Google annonce en effet le lancement en 2020 d’un compte courant avec la banque Citigroup. Le compte sera intégré à Google Pay. Les risques potentiels résultant de la pénétration de ce qu’elle nomme les BigTech font l’objet du dernier rapport du Financial Stability Board.[7]
Les algorithmes prédictifs et la question des biais des programmeurs
On en vient maintenant aux domaines où l’emploi des algorithmes pose des questions d’éthique très importantes. On peut commencer par les bases de données personnelles autres que celles construites par les grandes plateformes. Elles sont constituées par les banques et les compagnies d’assurance sur leurs clients et leur servent lors des demandes d’emprunt ou d’établissement des contrats d’assurance: revenu, âge, nombre d’enfants à charge, accidents, maladies, etc. Si la base de données est suffisamment grande, elle permet de recourir à l’apprentissage machine (machine learning) où une fois qu’un logiciel a été créé pour une fonction donnée, un processus d’auto-apprentissage est enclenché. La banque ou l’assurance pourra entrer les caractéristiques d’un nouveau client potentiel dans la base de données, demander à des algorithmes de répondre à des questions, ce qu’ils feront en généralisant à partir des cas accumulés.
Partant du constat que «les algorithmes s’immiscent de plus en plus dans notre quotidien», une équipe de chercheurs français a publié début 2019 une étude sur l’usage des algorithmes aux conclusions très prudentes. Elle est organisée autour des notions de neutralité, de loyauté et d’équité.[8] Pour Cathy O’Neil, spécialiste états-unienne de l’IA, cette prudence n’est pas de mise. C’est l’alarme qu’il faut sonner, notamment en ce qui concerne les modèles dits «prédictifs», utilisés pour anticiper les comportements individuels: capacités professionnelles, fiabilité financière, en matière pénale la propension à récidiver, etc. A partir des résultats de tests effectués dans plusieurs domaines, O’Neil montre qu’un «algorithme n’est en réalité qu’une opinion intégrée aux programmes», ajoutant l’avertissement suivant: «nous savons que les opinions peuvent conduire à des pratiques discriminatoires à l’encontre des personnes». Publié aux Etats-Unis il y a trois ans, son ouvrage est sorti en français il y a peu de temps. [9] A l’exception d’un entretien avec l’auteur dans Libération[10], il est passé inaperçu et est peu cité.
O’Neil rappelle la nécessité de s’interroger sur l’intérêt et la fiabilité des bases de données («rubbish in, rubbish out»), mais elle se concentre surtout sur leur conception (design). Les modèles encodent les choix de leurs concepteurs, tant du fait des questions posées que des facteurs subjectifs façonnés socialement. Il existe une tolérance à l’erreur de ces modèles, mais leur degré d’acceptabilité est nécessairement déterminé par les conséquences que ces erreurs peuvent comporter pour les individus. O’Neil considère que l’erreur de l’algorithme est acceptable si elle concerne l’efficacité du ciblage des publicités sur un moteur de recherche Internet, mais elle est très grave si elle affecte des individus dans leurs opportunités d’emploi, leur stabilité financière, leur accès au logement ou encore l’évaluation des taux de récidive en matière pénale à laquelle nous venons tout de suite.[11] Selon elle, les modèles prédictifs présentent de fait des limites rédhibitoires. Ils sont opaques et sans possibilité d’appel, les personnes qui y sont soumises l’ignorant et quand ils en ont connaissance ne sachant pas les critères pris en compte pour les évaluer. Leur usage engendre des boucles négatives auto-réalisatrices affectant en tout premier lieu les personnes les plus vulnérables et les plus pauvres (travail, crédit, accès à l’enseignement).
Les algorithmes nouveaux acteurs du système judiciaire
On en arrive à la question de la colonisation progressive du droit par l’IA. Compte tenu de ce qui vient d’être dit de la présence inévitable des biais, on comprend que l’emploi des algorithmes dans le domaine pénal soit particulièrement grave et ait fait l’objet d’une importante mise en garde d’Amnesty International.[12] C’est le cas aux Etats-Unis où un logiciel d’évaluation des risques de récidive décide de la libération conditionnelle d’individus incarcérés. Nommé COMPAS, son emploi remonte à 2013.[13]
 L’analyse des résultats de 7000 cas par les chercheurs de l’ONG ProPublica a mis en lumière les discriminations liées aux biais sur lesquels repose l’algorithme. Utilisé dans plusieurs Etats américains dans la phase de détermination ou d’exécution de la peine, COMPAS dispose d’une base de données constituée à partir d’un long questionnaire (137 questions) dont plusieurs questions sur les antécédents familiaux, mais aussi sur le revenu et les habitudes de consommation des individus.[14] A partir des réponses fournies et du casier judiciaire de la personne, une note individuelle est attribuée sur une échelle de 1 (faible risque) à 10 (haut risque). Sur la base de ces éléments et de sa conviction personnelle, le juge choisit la peine ou décide d’accorder la libération conditionnelle. Les chercheurs de ProPublica ont constaté que l’algorithme attribue aux populations afro-américaines un risque de récidive deux fois supérieur à celui des autres populations. D’autres analyses étasuniennes de sentencing (prononcement des peines) utilisant des méthodes quantitatives, telles que celle qui porte sur le mandat de dépôt en comparution immédiate ont fait apparaître des régularités quant au poids des marqueurs de marginalité sociale expliquant l’incarcération.[15]
L’analyse des résultats de 7000 cas par les chercheurs de l’ONG ProPublica a mis en lumière les discriminations liées aux biais sur lesquels repose l’algorithme. Utilisé dans plusieurs Etats américains dans la phase de détermination ou d’exécution de la peine, COMPAS dispose d’une base de données constituée à partir d’un long questionnaire (137 questions) dont plusieurs questions sur les antécédents familiaux, mais aussi sur le revenu et les habitudes de consommation des individus.[14] A partir des réponses fournies et du casier judiciaire de la personne, une note individuelle est attribuée sur une échelle de 1 (faible risque) à 10 (haut risque). Sur la base de ces éléments et de sa conviction personnelle, le juge choisit la peine ou décide d’accorder la libération conditionnelle. Les chercheurs de ProPublica ont constaté que l’algorithme attribue aux populations afro-américaines un risque de récidive deux fois supérieur à celui des autres populations. D’autres analyses étasuniennes de sentencing (prononcement des peines) utilisant des méthodes quantitatives, telles que celle qui porte sur le mandat de dépôt en comparution immédiate ont fait apparaître des régularités quant au poids des marqueurs de marginalité sociale expliquant l’incarcération.[15]
En France, comme le montre l’article de Cités, les partisans de l’emploi d’algorithmes dans le domaine du droit prédisent, ou plus exactement militent pour une évolution de la justice comportant un remplacement des formes de rationalité intrinsèques au procès civil ou pénal par des procédés automatisés.[16] Ainsi une série de petites entreprises «start-up» sont nées dans le domaine des algorithmes d’aide à la décision que l’on désigne du terme de «justice prédictive». Elles incluent les sociétés Prédictice, Juri Predis, LexisNexis (avec l’application Jurisdata Analytics), Predilex ou encore Case Law Analytics. Leur apparition date du milieu des années 2010 et leur déploiement, tout comme leur médiatisation, sont en grande partie liés à l’adoption en 2016 de la loi pour une République numérique préparée par Axelle Lemaire sous François Hollande. Certaines dispositions de ce texte, en effet, esquissent les conditions d’un accès totalement ouvert du numérique aux décisions de justice qui pourrait conduire vers une réforme de la justice intégrant pleinement les méthodes algorithmiques et permettant le déploiement, à grande échelle, des solutions de justice prédictive. A en croire leurs partisans, ils permettraient une accélération des procédures, une réduction des coûts, une favorisation de l’accès au droit, une réduction du stress des victimes et des accusés qui comparaissent.

Quels arguments peut-on leur opposer? En droit civil et commercial les méthodes algorithmiques prétendent fournir les moyens de remplacer le procès classique purement et simplement; c’est l’ambition des modes alternatifs de règlements des litiges en ligne. La «legaltech» a vu la création par des ingénieurs-entrepreneurs de «start-up» proposant des services juridiques. Différents types de litiges fréquents sont modélisés par des algorithmes. Une fois que sa nature a été définie, ils l’analysent selon un schéma prédéfini, relèvent les traits communs avec d’autres affaires précédemment traitées, calculent les taux de succès et proposent des solutions. Selon le site legal-tech.fr, il en existait 75 en avril 2017. Ils utilisent les bases de données à différents niveaux: recherche de documents juridiques, comptabilité, automatisation de la rédaction juridique, mise en œuvre de plateformes d’actions collectives, calculs de probabilité de gain d’un procès ou des montants d’indemnisation. Le grand défi de cette justice non étatique sera l’exécution de ses décisions: elle devra s’en remettre à la bonne volonté des parties.[17] Mais l’enjeu social est ailleurs. Focaliser la discussion sur une démocratisation de l’accès à une justice qui serait moins cher et offrirait en prime la réduction du stress des parties, c’est accepter que les arrêts ne construisent plus une jurisprudence mais alimentent simplement une base de données, qu’elle n’ait plus de possibilité de changer, en somme que la culture juridique et la constitution et l’évolution des normes cède la place à l’IA.
En matière pénale, l’objectif des partisans des algorithmes est de pouvoir se passer des raisonnements que mène un juge quand il applique une règle de droit. Or «la fonction essentielle (des juges du fond) n’est pas seulement l’interprétation et l’application de la règle de droit mais aussi et surtout la quali?cation des faits, leur interprétation juridique».[18] Celle-ci, insistent Stéphanie Lacour et Daniela Piana, «ne peut pas être modélisée sous la forme d’une règle d’implication inférant un résultat d’une proposition donnée par induction. Les algorithmes relèvent de calculs qui ne sont absolument pas comparables à la dialectique qu’un juge respecte pour parvenir à des décisions et dont la rédaction de ces dernières porte la trace. Ils ne s’inspirent pas plus, on l’imagine bien malgré le fait qu’on les présente souvent comme relevant de l’intelligence arti?cielle, du contexte historique, sociopolitique ou économique des normes applicables.»
La reconnaissance faciale instrument de contrôle politique de nature policière
On a vu plus haut le rôle d’avant-garde joué par Amazon dans ce domaine à des fins de surveillance de ses salariés. Le groupe a tout de suite commercialisé son logiciel de reconnaissance biométrique, Rekognition. Il l’a proposé à la police états-unienne des frontières ainsi qu’aux municipalités de grandes villes américaines dont certaines en font usage, notamment en Californie et en Floride.[19]

La biométrie regroupe l’ensemble des procédés automatisés permettant de reconnaître un individu à partir de la quantification de ses caractéristiques physiques, physiologiques ou comportementales (empreintes digitales, réseau veineux, iris des yeux, etc.). Ils permettent l’identification unique d’une personne à partir de certaines caractéristiques du visage à partir d’une photographie ou d’une vidéo (on parle alors de «gabarit»). L’algorithme permet de détecter des visages, de les analyser et de les comparer en temps réel. Une personne dont le visage est connu de la police peut ainsi être retrouvée parmi une foule. L’outil n’a qu’à mémoriser l’image de l’individu et parviendra, en principe, à l’identifier. Vendu comme produit par Cloud d’Amazon Web Services, le logiciel est particulièrement bon marché puisqu’il ne dépasse pas douze dollars par mois, pour toute une ville. Pourtant, selon des tests réalisés par l’ONG Union américaine pour les libertés civiles (ACLU), dont un sur des membres du Congrès, le système atteindrait seulement un niveau de certitude par défaut de 80%.[20] Si dans certains cas, ce seuil peut paraître acceptable, comme pour la reconnaissance d’objets ou d’animaux où l’enjeu est minime, il est loin d’être satisfaisant dit l’ACLU pour l’identification de personnes. Le débat a rebondi en mai 2018, lorsque l’association a révélé que la police d’Orlando a utilisé Rekognition pour un essai de reconnaissance en conditions réelles. Or dit l’ONG, «une identification inexacte pourrait coûter aux gens leur liberté ou même leur vie». Un test effectué par l’ACLU à San Francisco a rencontré le même niveau d’erreur.[21] Son usage s’est étendu vers d’autres pays, dont la France où la municipalité de Nice a mis la reconnaissance faciale en place dans trois lycées. L’usage de données biométriques est réglementé par le Règlement Général sur la Protection des Données (RGPD) administré par la CNIL.[22] L’avis rendu en novembre par cet organisme n’est pas contraignant et le langage utilisé assez accommodant.[23]
Du côté de l’utilisation de la reconnaissance faciale par les appareils étatiques, c’est indéniablement la Chine qui est en tête. On y trouve un système dit de «crédit social» (SCS) que le Parti communiste chinois veut mettre en place à partir de 2020. Celui-ci est d’ores et déjà testé dans certaines grandes villes, et attribue une note aux habitants selon leur niveau «d’honnêteté». S’ils sont endettés ou qu’ils traversent la rue au feu rouge,[24] ils perdent des points et peuvent se voir infliger une punition, telle celle de se voir interdire de prendre l’avion ou celle infamante de l’affichage du visage sur des écrans géants. [25] Pour faire adhérer la population à ces systèmes, les grandes entreprises jouent un rôle essentiel. Ainsi Alibaba, géant de la vente en ligne, permet à sa clientèle de s’inscrire volontairement à Sesame Credit, où un algorithme récupère leurs données sur le temps passé en ligne, l’argent dépensé et l’historique des paiements. Les mieux notés gagnent un accès à des crédits avantageux. C’est en partie grâce à de tels exemples que le système de notation est extrêmement populaire. Lors d’un sondage, 80% des 2200 personnes questionnées ont jugé les «systèmes de crédit social» de façon positive ou très positive. Xi Jiping ne se cache pas de vouloir s’en servir non seulement à des fins de répression politique mais aussi de contrôle social plus largement. Dans un entretien donné au Quotidien du peuple, il a affirmé qu’il était «nécessaire d’explorer l’utilisation de l’IA dans la collecte, la production, la distribution, la réception et le retour d’informations afin d’améliorer de manière globale la capacité de guider l’opinion publique».[26]
 C’est ainsi que la Chine est en train de mettre en place le système de reconnaissance faciale le plus puissant au monde, qui aura la capacité d’identifier l’un de ses 1,3 milliard de citoyens en trois secondes, l’objectif étant de faire correspondre le visage de quelqu’un à sa photo d’identité avec une précision d’environ 90%. Le système peut être connecté à des réseaux de caméras de surveillance et utilisera des installations cloud de grappe ou de cluster de serveurs (computer clusters) pour connecter des centres de stockage et de traitement de données situés dans tout le pays.[27] Se faisant l’apologue naïf de la bureaucratie du PCC, Gaspard Koenig rapporte «qu’il y a des caméras dans les salles de classe, pour repérer les réactions des étudiants aux discours des professeurs, afin d’améliorer les méthodes éducatives. Nous, cela nous rendrait hystérique. Les Chinois ont adapté l’IA avec enthousiasme, sans aucun frein, pas par cynisme, mais parce que cela correspond à leurs valeurs confucéennes et altruistes où la communauté prime ».[28]
C’est ainsi que la Chine est en train de mettre en place le système de reconnaissance faciale le plus puissant au monde, qui aura la capacité d’identifier l’un de ses 1,3 milliard de citoyens en trois secondes, l’objectif étant de faire correspondre le visage de quelqu’un à sa photo d’identité avec une précision d’environ 90%. Le système peut être connecté à des réseaux de caméras de surveillance et utilisera des installations cloud de grappe ou de cluster de serveurs (computer clusters) pour connecter des centres de stockage et de traitement de données situés dans tout le pays.[27] Se faisant l’apologue naïf de la bureaucratie du PCC, Gaspard Koenig rapporte «qu’il y a des caméras dans les salles de classe, pour repérer les réactions des étudiants aux discours des professeurs, afin d’améliorer les méthodes éducatives. Nous, cela nous rendrait hystérique. Les Chinois ont adapté l’IA avec enthousiasme, sans aucun frein, pas par cynisme, mais parce que cela correspond à leurs valeurs confucéennes et altruistes où la communauté prime ».[28]
Pour conclure: un défi démocratique sans précédent et un combat très difficile
Cette recherche a cherché à présenter de façon très synthétique les questions sociales et politiques majeures posées par les principaux usages des algorithmes: l’appropriation de données personnelles par les plateformes numériques et leur utilisation comme moyen d’accroître les ventes et les profits; l’introduction d’algorithmes comme acteurs des systèmes judiciaires; la surveillance étatique qualitativement accrue au moyen de la collecte et l’analyse de données notamment de reconnaissance faciale à des fins «sécuritaires».
Tel que je l’ai défini dans la première partie l’IA est le produit du capitalisme au stade qu’il a atteint en ce XXI° siècle et en retour il en renforce tous les traits qui font de lui un système qui entraîne l’humanité dans la barbarie. Les technologies de l’IA renforcent tous les mécanismes subjectifs de la servitude volontaire propre aux marchandises en même temps qu’elles offrent aux Etats des moyens dictatoriaux sans pareil. A l’heure de l’oligopole des plateformes numériques, dont les profits reposent sur la vente d’espaces publicitaires qui ont pour but de réduire le salarié-citoyen au statut de consommateur, il devient encore plus difficile qu’il ne l’était déjà de lutter pour des formes de production et de consommation qui correspondraient aux exigences du changement climatique et de la raréfaction des ressources.
Comme vient de le démontrer un rapport de l’ONG Avaaz au terme de recherches sur les enjeux climatiques sur YouTube, l’internaute y est confronté à des vidéos climatosceptiques.[29] Les gouvernements pourraient acheter des créneaux pour populariser les enjeux du changement climatique mais ils sont dans des rapports d’infériorité politique vis-à-vis du pouvoir oligopolistique des plateformes. Le rôle de l’IA dans la mise en place de la dictature de Xi Jiping, dictature personnelle à la tête d’un appareil revigoré attaché à réduire les espaces de lutte des ouvriers et des étudiants, n’a pas vocation à demeurer chinois. En cas d’aggravation des facteurs de crise économique et sociale mondiale, d’autres Etats y recourront.
Pour l’instant le danger immédiat vient non des Etats mais des plateformes numériques. C’est dans le rapport états-unien publié à Chicago que j’ai déjà cité longuement dans la première partie, que l’on trouve l’appréciation la plus lucide des menaces que les plateformes, notamment Google et Facebook, font peser sur les libertés démocratiques. Selon ce rapport, elles ont à la fois un immense pouvoir économique en tant que sociétés avec les valorisations boursières les plus élevées du monde, avec des réserves de trésorerie combinées de centaines de milliards de dollars. Elles les utilisent pour influencer la politique. Alphabet (Google), Amazon et Facebook sont classés au deuxième, sixième et neuvième rangs en matière de lobbying direct. Leur rôle de plus en plus fort en tant que médias permet aux plateformes de façonner le discours public. Il les autorise à réclamer les exemptions du premier amendement pour s’opposer à tout règlement qui tente de contrôler leurs actions. Leur taille, leur complexité et leur opacité absolue compliquent le développement d’outils réglementaires efficaces, car les plates-formes peuvent toujours utiliser les asymétries d’information pour contourner les règlements sans trop de sensibilisation.
A cet égard, les plateformes ressemblent aux grandes banques dans leur capacité d’esquiver le contrôle des organismes de réglementation les plus puissants. La connectivité tenant à leur nature de réseau leur permet de mobiliser une base d’utilisateurs pour contester toute initiative politique qui les désavantage. Sous cet aspect, elles ont des «pouvoirs d’adhésion» semblables à la National Rifle Association (NRA). Enfin en se présentant comme champions nationaux, elles jouent constamment la carte de «l’intérêt national» chaque fois que leurs intérêts sont menacés. Le rapport conclut que «Google et Facebook ont la puissance d’ExxonMobil, du New York Times, de JPMorgan Chase, de la National Rifle Association et de Boeing réunis. En outre, ce pouvoir combiné repose entre les mains de seulement trois personnes.» [30]
Si on considère la liberté de la presse comme une liberté démocratique fondamentale à laquelle les dictatures s’attaquent, force est de regarder Google et Facebook d’un nouvel œil. Pas besoin de policiers pour venir mettre des scellés aux portes des journaux. Pas besoin d’un Quotidien du Peuple aux mains du Parti Communiste Chinois. Les plateformes s’en chargent. Un des très grands intérêts du rapport de l’université de Chicago est l’attention qu’il porte à l’information et à la presse.[31] «Facebook est maintenant le deuxième plus grand fournisseur de nouvelles en termes de part d’attention (attention share) aux Etats-Unis. Au Royaume-Uni, Facebook est troisième, Google est cinquième, et Twitter est dixième». Selon le rapport «en organisant les nouvelles que les téléspectateurs reçoivent, ils se sont effectivement appropriés le rôle que les rédacteurs en chef de journaux possédaient (….), de très nombreux de points de vue différents ont été remplacés par un duopole (…), la présentation éditoriale vise à maximiser le temps d’un spectateur sur la plate-forme, avec peu d’attention à la qualité du contenu, la présentation des nouvelles est personnalisée, favorisant une fragmentation des citoyens et compromettant la capacité des différents groupes politiques de parler les uns aux autres.»
La dévastation de l’industrie de la presse aux Etats-Unis par les deux plateformes est analysée en détail dans le rapport. Les journaux locaux ont été particulièrement touchés: au moins 1800 journaux ont fermé leurs portes aux Etats-Unis depuis 2004, laissant plus de 50% des comtés américains sans quotidien local. Depuis la montée en puissance des journaux à sensation le soutien du journalisme d’investigation a été un enjeu. Mais il exige d’importants investissements dans la durée, dont le rendement ne peut pas être facilement approprié par l’investisseur, puisque le reportage peut être repris par d’autres Dans le secteur oligopolistique, les grands journaux ont pu financer les reportages d’investigation avec leurs profits et en tirer des avantages sous forme d’une réputation accrue. La réduction du nombre et de la rentabilité des journaux a fortement réduit les fonds consacrés à cette activité. La situation est particulièrement grave au niveau local. Le New York Times et le Washington Post ont les ressources pour mener des investigations au plan national, mais la corruption locale à Topeka, Kansas, ou Montgomery, Alabama, est à peine d’intérêt national. Lorsque la capacité d’investigation disparaît, la qualité de la gestion administrative locale peut en souffrir. La fermeture de journaux locaux a également tendance à diminuer à la fois la quantité d’informations dont disposent les électeurs lors des élections locales et la participation électorale. «D’où la crainte que la démocratie locale ne meure dans l’obscurité».[32]
En France trois terrains
La lutte contre l’IA sur les terrains où elle est possible relève de la question démocratique au sens où le marxisme révolutionnaire l’a entendue dans d’autres contextes.[33] Il est possible d’identifier plusieurs terrains. Le premier est celui de la reconnaissance faciale sécuritaire. Mediapart a publié la lettre commune que 124 associations, dont la Ligue des droits de l’Homme, le Syndicat de la magistrature, le Syndicat des avocats de France, Solidaires et Attac ont signée en décembre 2019 pour demander l’interdiction de cette technologie dans le champ sécuritaire. La vidéosurveillance a son lobby, l’Association nationale de vidéoprotection (AN2V) qui est très offensive politiquement alors que la CNIL se borne à réclamer un «débat à la hauteur des enjeux». Ensuite il y a celui de la surveillance numérique en milieu scolaire et ici encore le quasi-assentiment de la quasi-acceptation de la reconnaissance faciale des élèves par la CNIL, question dont tous les syndicats de l’enseignement public devraient se saisir. Puis il y a l’emploi projeté des algorithmes dans les procédures judiciaires et les décisions juridiques où toutes les initiatives qui le combattraient devraient être soutenues. Enfin il y a la question des aides publiques à la presse écrite quand celles-ci sont menacées. La préparation d’un rapport à la demande d’Edouard Philippe par le député LREM Cédric Villani en 2017 et sa présentation en 2018[34] annoncent de nouvelles mesures législatives en faveur de l’IA dès que l’agenda gouvernemental le permettra. Donc la plus grande vigilance s’impose. (Fin)
[1] The Economist, 8 octobre 2019, p.11.
[2] https://www.newsweek.com/how-artificial-intelligence-transform-wall-street-560637 Les chiffres sont spectaculaires : https://www.bloomberg.com/news/articles/2018-04-30/goldman-trading-desk-that-once-had-500-people-is-down-to-three et https://bitnewstoday.com/market/technology/neural-networks-in-trading-goldman-sachs-has-fired-99-of-traders-replacing-them-with-robots/
[3] Voir https://investorjunkie.com/41363/robo-advisors-vs-financial-advisors/ et la liste des mieux notés https://www.investopedia.com/best-robo-advisors-4693125
[4] US House of Representatives, Task Force on Artificial Intelligence, Robots on Wall Street: The Impact of AI on Capital Markets and Jobs in the Financial Services Industry, December 6, 2019 https://www.ft.com/content/0b660446-1827-11ea-9ee4-11f260415385
[5] Voir par exemple Thomas Philippon, The Great Reversal : How America Gave Up on Free Markets, Harvard University Press, 2019. La démonstration chiffrée s’accompagne d’une explication où le rôle principal est attribué au lobbying et aux contributions des oligopoles au financement des campagnes électorales.
[6] www.Big%20Tech%20Summoned%20to%20Washington%20for%20Antitrust%20Hearing%20-%20WSJ.pdf
[8] Bertail Patrice, Bounie David, Clémençon Stephan et Waelbroeck Patrick (dont trois travaillent dans les laboratoires informatiques de France Télécom, Algorithmes : biais, discrimination et équité. https://www.telecom-paris.fr/wp-content-EvDsK19/uploads/2019/02/Algorithmes-Biais-discrimination-equite.pdf
[9] Cathy O’Neil, Weapons of Math Destruction. How Big Data Increases Inequality and Threatens Democracy, Crown, 2016, publié en français sous le titre Algorithmes : la bombe à retardement, Paris, Les Arènes, 2018,
[11] https://www.propublica.org/article/how-we-analyzed-the-compas-recidivism-algorithm
[13] https://www.theatlantic.com/technology/archive/2018/01/equivant-compas-algorithm/550646/
[14] Julia Angwin, Sample-COMPAS-Risk-Assessment-COMPAS-”CORE”. https://www.documentcloud.org/documents/2702103-Sample-Risk-Assessment-COMPAS-CORE.html
[15] https://en.wikipedia.org/wiki/Sentencing_disparity
[16] Stéphanie Lacour et Daniela Piana, Faites entrer les algorithmes ! Regards critiques sur la « justice prédictive », Revue « Cités » Presses Universitaires de France, 2019/4 N° 80
[17] http://lesaf.org/wp-content/uploads/2019/04/16-brevelecture-DC.pdf
[18] Jean Louis Billon, « L’aide informatisée à la décision judiciaire », Revue internationale de droit comparé, vol. XLII, n° 2, « Études de droit contemporain », avril-juin 1990, p. 855-861. Cité par Stéphanie Lacour et Daniela Piana.
[19] L’historique se trouve sur https://en.wikipedia.org/wiki/Amazon_Rekognition
[20] En français voir https://www.usine-digitale.fr/article/rekognition-le-systeme-de-reconnaissance-facial-d-amazon-fait-debat.N725499
[22] https://www.cnil.fr/fr/la-videosurveillance-videoprotection-dans-les-etablissements-scolaires
[23] https://www.cnil.fr/sites/default/files/atoms/files/reconnaissance_faciale.pdf et https://www.la-croix.com/France/Securite/Cnil-cherche-voix-reconnaissance-faciale-2019-11-04-1201058470
[26] https://korii.slate.fr/tech/chine-laboratoire-dictature-20
[27] https://www.scmp.com/news/china/society/article/2115094/china-build-giant-facial-recognition-database-identify-any. On parle de grappe ou de cluster de serveurs (computer clusters) pour désigner des techniques du cloud consistant à regrouper des ordinateurs indépendants appelés nœuds (node ), afin de permettre une gestion globale.
[28] Gaspard Koenig, interview dans Marianne au sujet de son livre «La fin de l’individu. Voyage d’un philosophe au pays de l’intelligence artificielle». Editions de L’observatoire, 2019
[29] On trouve par exemple, sur YouTube une vidéo intitulée «L’urgence climatique est un leurre» déjà visionnée plus de 600’000 fois. Un physicien, François Gervais y développe des positions réfutées par l’immense majorité des scientifiques. https://www.lemonde.fr/les-decodeurs/article/2020/01/17/comment-la-desinformation-sur-le-climat-se-diffuse-et-se-finance-sur-youtube_6026186_4355770.html
[30] Stigler Committee on Digital Platforms, op. cit., pages 14-15. Disponible à https://research.chicagobooth.edu/-/media/research/stigler/pdfs/digital-platforms—committee-report—stigler-center.pdf?la=en&hash=2D23583FF8BCC560B7FEF7A81E1F95C1DDC5225E
[31] Ibid, pages 9-11
[32] Ibid., page 11
[33] Voir le texte classique de Lénine de 1905, Deux tactiques de la social-démocratie dans la révolution démocratique. https://www.marxists.org/francais/lenin/works/1905/08/vil19050800g.htm
[34] Cédric Villani, Donner un sens à l’intelligence artificielle. Pour une stratégie nationale et européenne. https://www.enseignementsup-recherche.gouv.fr/cid128577/rapport-de-cedric-villani-donner-un-sens-a-l-intelligence-artificielle-ia.html
Soyez le premier à commenter